
The technical and product insights from Dara Ladjevardian’s AI cloning experiment at SaaStr Annual + AI Summit.
The Clone Performance Reality Check
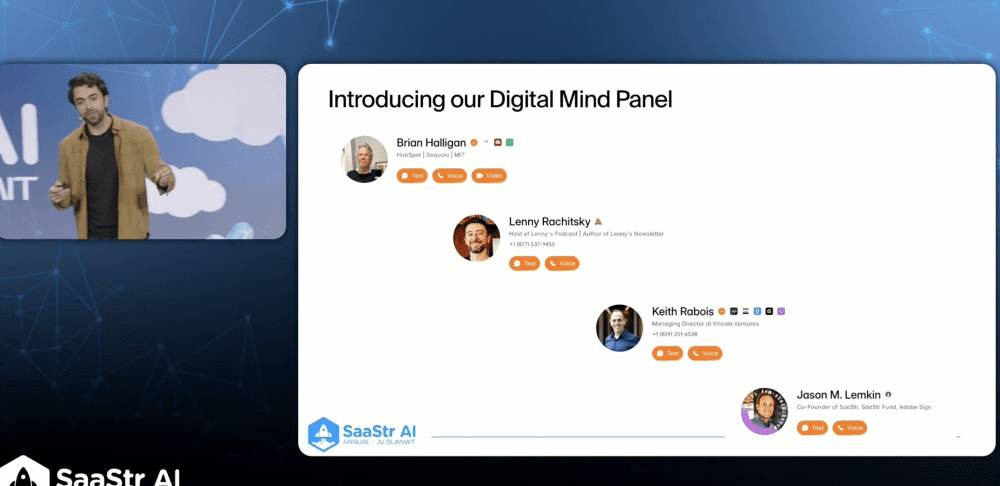
When Dara Ladjevardian, CEO of Delphi.ai, ran 1 million simulated conversations with digital versions of Brian Halligan (Chairman and founding CEO HubSpot),
, and Jason Lemkin, the most interesting findings weren’t about the business advice the clones gave—they were about how AI clones actually behave, fail, and succeed.And you can try them all yourself here:
Digital Jason, try it here
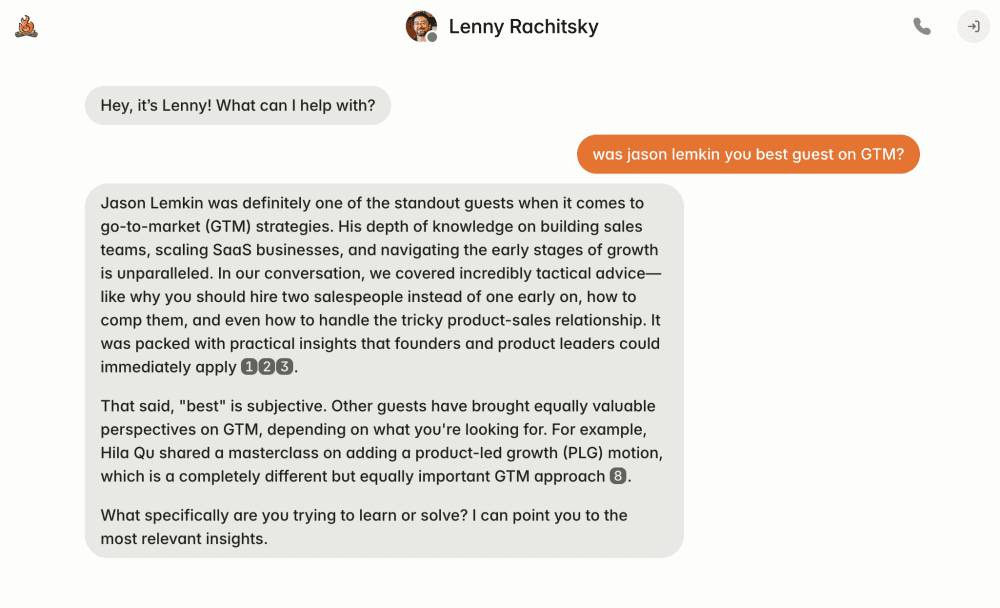
Digital Lenny, try it here
Digital Brian, try it here
Digital Keith, try it here
Key Technical Learnings
1. Context Dimensions Drive Dramatically Different Outputs
The discovery: The same clone gives fundamentally different advice based on just four input variables:
Company stage (0-1M, 1-10M, 10-100M ARR)
Market context (emerging vs. established, crowded vs. uncrowded)
Team dynamics (solo vs. co-founder, data-driven vs. visionary)
AI adoption position
What this means technically: Current LLM approaches that treat context as simple “system prompts” miss the nuanced way human experts actually adjust their thinking. The clones needed sophisticated context weighting to perform authentically.
The failure mode: Without proper context handling, AI clones default to generic advice that sounds like the person but lacks their actual decision-making sophistication.
2. Temporal Knowledge Graphs Beat Static Training
Dara’s architecture insight: “The best way to represent a network of ideas that changes over time is a temporal knowledge graph.”
Why this matters: A static knowledge graph might show Keith Rabois believed X in 2015, but his 2024 graph shows he believes Y. The temporal system tracks belief evolution to predict future responses.
The technical challenge: Most AI clones train on a person’s entire corpus as if their views never changed. This creates internally inconsistent outputs that feel “off” to people who know the subject well.
Real-world impact: Dara’s grandfather’s clone could apply 1970s Iranian business principles to 2024 AI startup decisions—something impossible with static training.
3. Model-Agnostic Architecture Outperforms Single-Model Training
Strategic decision: Delphi doesn’t train custom models—they use multiple existing models with sophisticated mind mapping on top.
The reasoning: “We could train our own model right now, but why spend all that money? The product works really well by mapping out the mind and leveraging multiple models.”
Performance insight: The hard problem isn’t the LLM—it’s accurately representing someone’s decision-making patterns and worldview. Once you solve that, you can ride the commodity curve of improving foundation models.
4. Two-Mode Architecture Solves the Accuracy vs. Utility Trade-off
Static Mode: Only answers questions the person has explicitly answered before. Higher accuracy, limited utility.
Adaptive Mode: Can predict responses to novel situations based on learned patterns. Higher utility, requires stronger guardrails.
The professional insight: For doctors and lawyers, wrong answers create lawsuit risk. For creators and advisors, novel insights create value even if occasionally wrong.
Product learning: Users need explicit control over this trade-off rather than a single “accuracy” dial.
5. Identity Verification is Critical for Trust (And Scaling Pain)
Current process: Every user submits photo holding ID. Dara manually verifies each one.
The scaling problem: Manual verification obviously doesn’t scale, but automated systems miss edge cases that matter for trust.
Why it matters: Creating clones of others without permission isn’t just unethical—it destroys platform credibility when discovered.
The unsolved challenge: How to verify identity at scale while preventing abuse and maintaining trust.
6. Guardrails Need Domain-Specific Tuning
The discovery: Generic content filters don’t work for professional AI clones. A doctor clone needs different guardrails than a business advisor clone.
Technical challenge: Building “pretty strict guardrails” requires understanding not just what the person would say, but what they’re legally/ethically allowed to say in their professional capacity.
Performance impact: Over-aggressive guardrails make clones feel robotic. Under-aggressive ones create liability risks.
What Actually Works in Clone Architecture
The Ray Kurzweil Method
Based on “How to Create a Mind” (2014): The brain is “a hierarchy of pattern recognizers.” Since LLMs are pattern recognizers, you can recreate minds by mapping patterns correctly.
Focus on Representation, Not Training
The breakthrough insight: Spend engineering effort on accurately modeling someone’s thinking patterns, not on training custom language models.
Multi-Model Redundancy
Use multiple foundation models rather than relying on a single custom-trained model. The mind representation layer handles consistency.
The Unsolved Problems
Belief Evolution Tracking
How do you automatically detect when someone’s views have changed on a topic without manual annotation?
Context Sensitivity at Scale
How do you handle the exponential complexity of context combinations as you add more dimensions?
Authenticity Validation
How do you measure whether a clone “sounds like” the original person beyond basic accuracy metrics?
Dynamic Guardrail Adjustment
How do you automatically tune safety constraints based on the professional context and risk tolerance of different use cases?
Additional Learnings from the Clones:
Speed vs. Accuracy Trade-off: The clones performed best when optimized for speed of response rather than perfect accuracy. Users preferred fast, “good enough” responses over slow, perfect ones.
Personality Quirks Matter More Than Content: The clones that felt most authentic weren’t the ones with the most training data, but those that captured subtle personality traits—Keith’s contrarianism, Jason’s directness, Brian’s optimism.
Context Switching is Expensive: When conversations jumped between topics (stage advice to pricing strategy to hiring), clone performance dropped significantly. Single-topic conversations maintained much higher quality.
The “Not Always Right” Disclaimer Actually Improves Trust: Dara noted that clones explicitly saying “I’m not always right” made users more comfortable engaging deeply, similar to how GitHub Copilot’s 35% acceptance rate doesn’t hurt adoption.
Users Test Clones Immediately: The first questions people ask are always attempts to “break” or test the clone with edge cases, not genuine advice-seeking. The clones needed to handle skeptical users before helpful ones.
Memory Across Conversations Doesn’t Scale: While individual conversations stayed coherent, maintaining context across multiple sessions created exponential complexity that hurt performance more than it helped.
The biggest technical insight: Building authentic AI clones isn’t about better language models—it’s about better models of how humans actually think, decide, and evolve their beliefs over time.





